昨天以 ML 系統設計來看模型開發的各個面向,今天我們用 MNIST 來示範 Rust 怎麼訓練與輸出模型。
所以今天的擬人化 Ferris 也來學學怎麼辨識手寫數字囉!
深度學習是機器學習領域最令人興奮的發展之一,而更讓人興奮的是 Rust 也可以使用 PyTorch 與 Hugging Face!
事實上,如果想要一個高性能的深度學習研究環境,那麼 Rust 或許最好的工具之ㄧ,因為它提供了比 Python 更好的可移植性、性能以及更加方便的 Packaging 能力 (例如可以利用 Cargo 將預訓練模型打包並提供給他人)。
在這次系列文的專案 [Day 10] - 鋼鐵草泥馬 🦙 LLM chatbot 🤖 (1/10)|專案簡介 中,我們已經示範過如何使用 Hugging Face 了。
今天就來示範如何在 Rust 中使用 PyTorch,直接升級我們的 ML 文明,從石器時代的火把 (Torch) 進化到現代的手電筒 (Electric Torch) 吧!
我們今天將使用 Laurent Mazare 所開發的 tch-rs crate,它將 Rust 與 PyTorch 進行綁定,可以視為 Rust 版的 PyTorch。
其實 tch-rs 是對 PyTorch 的 C++ API (又稱為 libtorch) 的封裝,因此使用上會與 PyTorch 有些許不同,但基本上大同小異,有需要時可以參考 官方文件。
根據 tch-rs 的說明,我們首先要在系統上安裝 Libtorch (也支援使用 Python PyTorch),這裡使用 unbuntu 作為示範,若想在 Mac 上使用請參考這個 issue,而 Windows 則可以參考 這裡兒。
而安裝主要有兩個步驟:
要安裝 Libtorch 的第一步就是到 官網下載,這裡為了說明方便,使用 CPU 的版本。
可以看到官網上有兩個連結,兩者其實差別不大 (先爆雷一下,我們要選擇 cxx11 ABI),但如果環境中有 PyTorch 就得注意一下:
知道要下載哪個之後,下載的部份就簡單了,用 wget 再解壓縮即可:
>>> wget https://download.pytorch.org/libtorch/cpu/libtorch-cxx11-abi-shared-with-deps-2.1.0%2Bcpu.zip
>>> unzip libtorch-shared-with-deps-2.1.0+cpu.zip
若不想安裝在本機,可以參考 libtorch location
下載並解壓縮之後,得設定相關的環境變數 (這部分參考 Libtorch Manual Install 與 Error loading shared libraries)。
請把下面的程式碼加到 .bashrc 或 .zshrc 中:
export LIBTORCH=/home/ubuntu/libtorch
export LIBTORCH_INCLUDE=/home/ubuntu/libtorch
export LIBTORCH_LIB=/home/ubuntu/libtorch
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:"/home/ubuntu/libtorch/lib:$LD_LIBRARY_PATH"
export PATH="/home/ubuntu/libtorch:$PATH"
安裝與設定好環境變數後,就可以來快速地測試看看了:
cargo new 一個新的專案。[dependencies] 區塊加上 tch="0.14.0"。use tch::Tensor;
fn main() {
let t = Tensor::from_slice(&[3, 1, 4, 1, 5]);
let t = t * 2;
t.print();
}
cargo run! 如果沒有問題應該可以看到終端機印出以下訊息: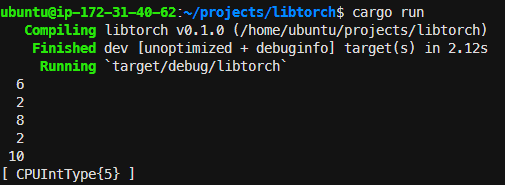
🏮 今天完整的程式碼可以拉到底下 的 Step7: Put it together 區塊與最後的 Step 8:測試訓練好的模型 找到!
Rust 是一種效能極高的系統程式語言,非常適合用來訓練深度學習模型。
使用 PyTorch Rust 綁定最大的優點在於,它可以讓我們將 PyTorch 模型打包成可重現的模型。
因此我們可以將你的模型分發給其他人,而他們可以使用相同的工具來訓練和部署模型。
這裡參考官方的 MNIST 範例進行 CNN 模型訓練與將模型存為 TorchScript 格式。
使用 tch-rs 訓練模型跟使用 PyTorch 的概念是相同的,一樣要定義模型架構、優化器,以及實作前向傳播。
要訓練模型首先就是要下載資料,請到 Yann LeCun's MNIST 頁面下載以下四個檔案 (它會叫你登入,所以請直接用下面的超連結下載):
有了資料後,我們首先載入 MNIST 資料:
let m = vision::mnist::load_dir("data").unwrap();
這裡利用了 MNIST 的輔助模組,會自動處理上面下載到 data 資料夾的資料。
其中訓練圖片與標籤會在訓練模型時使用,而測試圖片和標籤則會用於估計驗證誤差。
class Model(nn.Module))在 tch-rs 中定義模型的方式也和 PyTorch 一樣有兩種:
struct) 定義模型的參數,接著實作其 new 建構子以初始化參數,最後為此結構體實作 nn::ModuleT trait 的 forward_t() 方法,這裡會使用此方法,請看下方範例。根據上述的流程,我們可以如下建立簡單的 CNN:
#[derive(Debug)]
struct Net {
conv1: nn::Conv2D,
conv2: nn::Conv2D,
fc1: nn::Linear,
fc2: nn::Linear,
}
impl Net {
fn new(vs: &nn::Path) -> Net {
let conv1 = nn::conv2d(vs, 1, 32, 5, Default::default());
let conv2 = nn::conv2d(vs, 32, 64, 5, Default::default());
let fc1 = nn::linear(vs, 1024, 1024, Default::default());
let fc2 = nn::linear(vs, 1024, 10, Default::default());
Net { conv1, conv2, fc1, fc2 }
}
}
impl nn::ModuleT for Net {
fn forward_t(&self, xs: &Tensor, train: bool) -> Tensor {
xs.view([-1, 1, 28, 28])
.apply(&self.conv1)
.max_pool2d_default(2)
.apply(&self.conv2)
.max_pool2d_default(2)
.view([-1, 1024])
.apply(&self.fc1)
.relu()
.dropout(0.5, train)
.apply(&self.fc2)
}
}
在建立擁有多個權重和 bias 參數的模型時,我們使用 tch::nn::VarStore 來追蹤這些變數並讓優化器知道它們的存在:
let vs = nn::VarStore::new(Device::cuda_if_available());
let net = Net::new(&vs.root());
let opt = nn::Optimizer::adam(&vs, 1e-4, Default::default());
其中第一行建立了用以儲存模型結構與追蹤參數的 VarStore,而優化器則選用備受寵愛的 Adam。
其中 Device::cuda_if_available(),跟使用 Python 時所遵循的最佳實踐 Device-agnostic code 是一樣的。
訓練模型的流程就跟 PyTorch 一樣,請參考 The Unofficial PyTorch Optimization Loop Song!
而這裡一樣使用小批次進行訓練,可以看到 Rust 的迭代器能很優雅地使用 Functional programming 的形式來走訪並洗牌訓練集:
for epoch in 1..100 {
for (bimages, blabels) in m.train_iter(256).shuffle().to_device(vs.device()) {
let loss = net
.forward_t(&bimages, true)
.cross_entropy_for_logits(&blabels);
opt.backward_step(&loss);
}
let test_accuracy =
net.batch_accuracy_for_logits(&m.test_images, &m.test_labels, vs.device(), 1024);
println!("epoch: {:4} test acc: {:5.2}%", epoch, 100. * test_accuracy,);
以下程式碼可以將模型儲存成 Torchscript 的格式,注意我們使用 VarStore 的 .freeze() 方法將參數凍結以輸出模型:
vs.freeze();
let mut closure = |input: &[Tensor]| vec![net.forward_t(&input[0], false)];
let model = CModule::create_by_tracing(
"MyModule",
"forward",
&[Tensor::zeros([784], FLOAT_CPU)],
&mut closure,
)?;
model.save("model.pt")?;
其中要注意是 tch::jit::CModule::create_by_tracing 需要傳入模型的輸入尺寸,也就是 MNIST 的 784 維。
把上面所有的程式碼整理一下放進 src/main.rs 就可以組成一個簡單的訓練腳本,並且會將驗證準確率最高的權重輸出成 Torchscript 模型。
注意這裡因為只有使用 CPU 所以把輸出的數值型別寫死為 kind::FLOAT_CPU,若要使用 GPU 也可以透過額外撰寫邏輯判斷來給定型別即可:
use anyhow::Result;
use tch::{kind::FLOAT_CPU, nn, nn::ModuleT, nn::OptimizerConfig, CModule, Device, Tensor};
#[derive(Debug)]
struct Net {
conv1: nn::Conv2D,
conv2: nn::Conv2D,
fc1: nn::Linear,
fc2: nn::Linear,
}
impl Net {
fn new(vs: &nn::Path) -> Net {
let conv1 = nn::conv2d(vs, 1, 32, 5, Default::default());
let conv2 = nn::conv2d(vs, 32, 64, 5, Default::default());
let fc1 = nn::linear(vs, 1024, 1024, Default::default());
let fc2 = nn::linear(vs, 1024, 10, Default::default());
Net { conv1, conv2, fc1, fc2 }
}
}
impl nn::ModuleT for Net {
fn forward_t(&self, xs: &Tensor, train: bool) -> Tensor {
xs.view([-1, 1, 28, 28])
.apply(&self.conv1)
.max_pool2d_default(2)
.apply(&self.conv2)
.max_pool2d_default(2)
.view([-1, 1024])
.apply(&self.fc1)
.relu()
.dropout(0.5, train)
.apply(&self.fc2)
}
}
fn main() -> Result<()> {
let m = tch::vision::mnist::load_dir("data")?;
let mut vs = nn::VarStore::new(Device::cuda_if_available());
let net = Net::new(&vs.root());
let mut opt = nn::Adam::default().build(&vs, 1e-4)?;
let mut best_accuracy = 0.0;
for epoch in 1..100 {
vs.unfreeze();
for (bimages, blabels) in m.train_iter(256).shuffle().to_device(vs.device()) {
let loss = net.forward_t(&bimages, true).cross_entropy_for_logits(&blabels);
opt.backward_step(&loss);
}
let test_accuracy =
net.batch_accuracy_for_logits(&m.test_images, &m.test_labels, vs.device(), 1024);
println!("epoch: {:4} test acc: {:5.2}%", epoch, 100. * test_accuracy,);
if best_accuracy < test_accuracy {
best_accuracy = test_accuracy;
vs.freeze();
let mut closure = |input: &[Tensor]| vec![net.forward_t(&input[0], false)];
let model = CModule::create_by_tracing(
"MyModule",
"forward",
&[Tensor::zeros([784], FLOAT_CPU)],
&mut closure,
)?;
model.save("model.pt")?;
}
}
Ok(())
}
執行 cargo run 之後就能看到模型開始訓練了:
另外,這裡在每個 epoch 優化器更新權重之前使用了 .unfreeze() 將參數解凍,在更新權重之後再判斷其驗證準確率是否較之前還高,若準確率提高就把參數 .freeze() 凍結後輸出。
記得在 Cargo.toml 的
[dependencies]區塊加上anyhow = "1.0.75"
為了展現這個範例的泛用性與可攜性,我們這裡使用 Python 來看看測試集的表現,以下是測試程式碼 (看到闊別已久的 Python 是不是腦袋都放鬆一點了哈哈哈):
# The following code is partially copied from the official example.
# https://github.com/pytorch/examples/blob/ca1bd9167f7216e087532160fc5b98643d53f87e/mnist/main.py
import torch
from torchvision import datasets, transforms
import torch.nn.functional as F
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(
output, target, reduction="sum"
).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
model = torch.jit.load("model.pt")
device = torch.device("cuda")
test_kwargs = {"batch_size": 100}
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
dataset = datasets.MNIST("./data", train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(dataset, **test_kwargs)
test(model, device, test_loader)
下圖為在 Colab 中運行的結果 (記得要把模型與測試集傳上去):
可以看到使用 Rust 訓練的模型確實可以使用另一個平台來運行,展現出了可攜性!
當然也可以在 Rust 中使用其它人訓練好的模型,詳細請參考 Loading and Running a PyTorch Model in Rust
通常在 ML 領域提到 Rust 都會有些許疑慮,舉例來說,有些人可能會認為它是一種較新的語言,所以讓人擔心它是否能用於實際生產環境中。
但經過今天的範例,我們知道可以輕鬆的用 Rust 版的 PyTorch 訓練模型,並且在硬體允許時也能毫不費力的使用 GPU 進行推論。
在 [官方範例] 中還有 GAN, min-gpt, stable diffusion, 強化學習等案例可以參考,應用的層面非常廣泛。
而最後在這裡我還想提一下 sonos/tract 這個專案,它讓我們可以用 ONNX 等可攜式格式來打包模型,並將其分發給其他人。
像是專案 AndreyGermanov/yolov8_onnx_rust 便是使用 ONNX 來將 YOLOv8 以 Rust 部署。
YOLOv8 也可以直接輸出預訓練的 Torchscript 格式:
因此也能用今天介紹的 tch-rs 來實作物件辨識應用。
我認為這是 MLOps 的未來之一,而我們也可以使用 Rust 等系統程式設計語言來開發 MLOps 工具。
隨著越來越多人的投入與討論,也能使更多人得力於 Rust 開發的 MLOps 工具。
好啦,今天就這樣囉,明天見!
如果對畫圖有興趣的孩子也可以參考另一個專案 diffusers-rs,它支援 Stable Diffusion v1.5 與 v2.1,很帶勁的:


 iThome鐵人賽
iThome鐵人賽